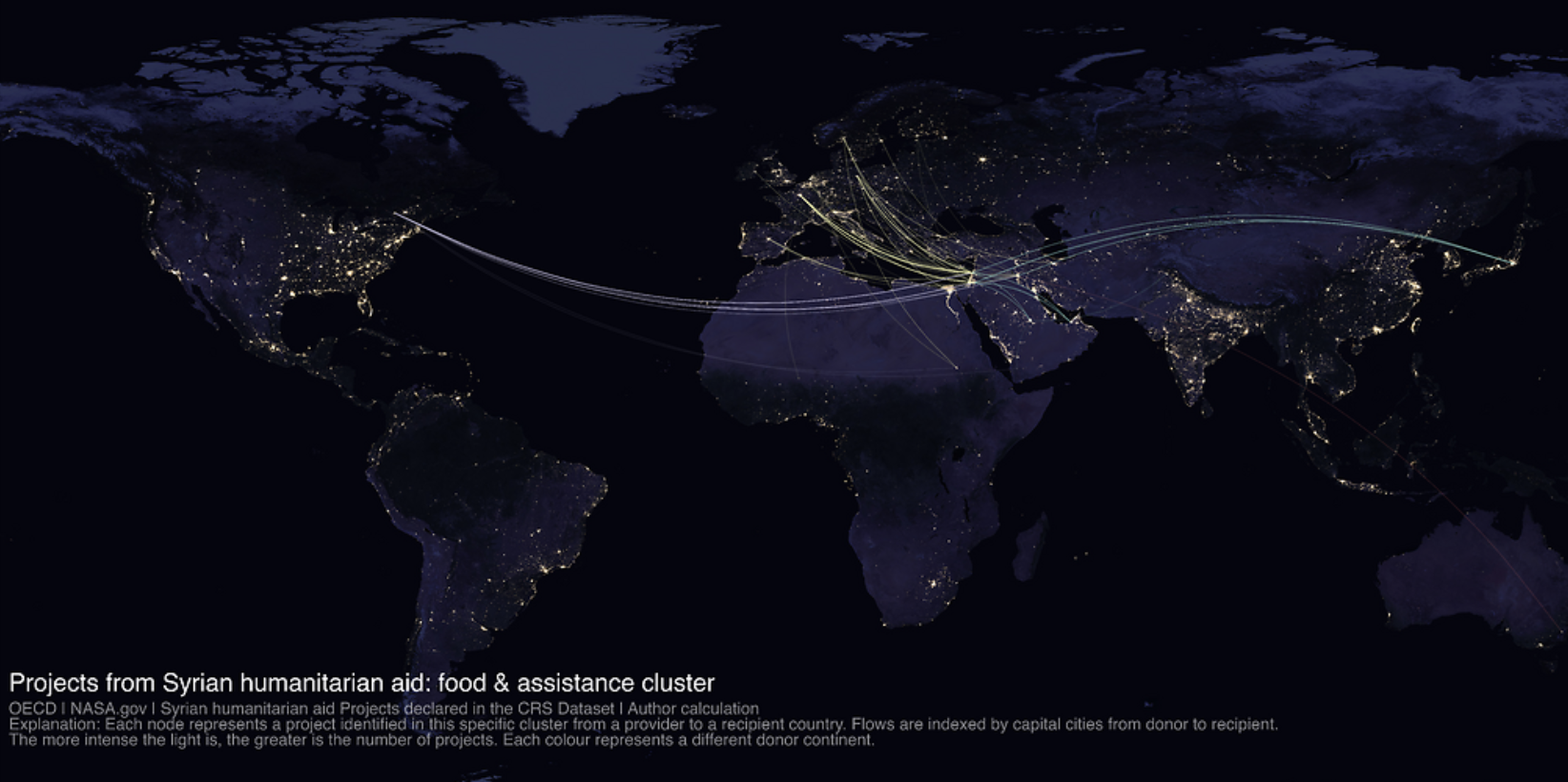
Every climate-COP reopens the same question: are rich-country pledges actually being delivered? The honest answer is surprisingly hard to produce, because the accounting system we use — OECD Rio markers — is a self-declaration regime. Donors decide which of their projects count as climate-relevant, and those decisions are not independently verified.
A project narrative — what the aid agency says the project does — is a richer, harder-to-game signal than a binary flag. This paper treats the narrative as the primary data, lets a clustering algorithm discover the latent topic structure of global aid, and then compares the resulting topic-based aggregates with the official ones. The divergence is the reporting gap.
- Can unsupervised topic modelling produce a more granular classification of development projects than sector codes or Rio markers?
- How much does narrative-based climate-finance accounting diverge from Rio-marker-based accounting?
- What hidden patterns, niches, and inconsistencies does the richer classification expose?